 Skip to content
Skip to content 










The computer chip landscape
In today’s article, we give you an overview of the shifting compute landscape and how it is affecting companies in the semiconductor value chain. You will learn about Intel, AMD, TSMC, and Nvidia, and the dynamics at play between these companies.
Note: For this segment, we strive for ease of understanding. As such, we will use analogies and may oversimplify things.
Not all computer chips are created equal. Some are purposefully built for high performance, while others are built for low power consumption. You can map out the different types of compute architectures along the spectrum of general purpose â†â†’ specific applications (see Figure 1).

On the left most end of the spectrum, you have a general purpose compute unit (CPU). These are generally very versatile. They can run a wide range of programs for multiple applications (they can run your Excel, office applications, design software, physics simulation, etc.). These CPUs are what Intel and AMD make. More on those two later.
Somewhere in the middle of the spectrum you have select chips that have relatively limited sets of applications. But what you lose in flexibility, you gain in efficiency. This area is where the Graphical Processing Units (GPUs) fall.
GPUs cannot run your Windows operating system, nor can they run your Office software, but they can run applications that require parallel processing a thousand times faster than CPUs can. The primary initial application for GPUs was for gaming, where the chips carried out highly parallel computation to render graphics. However, over the decades, two paradigm shifts occurred that made GPU the tool of choice for machine learning training:
- In 2001, Nvidia released GeForce 3, which had the first pixel shaders. Pixel shaders is software that enables the GPU to be more programmable (before shaders, GPUs were hard-coded, which limited their applications). Making GPUs programmable means that software developers can expand the usage of GPUs.
- In 2009, Andrew Ng from Stanford and his co-authors released a seminal paper that discussed the use of massively parallel cores in GPUs to accelerate machine learning training. The latest and most advanced version of Nvidia’s GPU is the RTX 30-Series. It has 10,496 cores. Contrast this to a typical CPU which has anywhere between 2 – 8 cores. Mind you, this is not an apples to apples comparison. Each core of a CPU is much more capable. But the high number of cores in a GPU is great for machine learning applications. What started off as an academic researcher’s tool in the early 2010s became serious business for Nvidia. More on Nvidia later.
As a side note: GPUs are also the tool of choice for miners who mine Ethereum. Ethereum’s mining algorithm, a proof-of-work algorithm, is designed to be iteratively solved using GPUs. The recent rise in Ethereum prices have led to a surge in demand of GPUs, leading to scarcity.
And finally, on the right hand side of the spectrum lies highly specialized chips. One popular example is Application-Specific Integrated Circuit Sets (ASIC). These are dedicated chips built for one task and one task only. Two primary applications of ASICs are:
- For bitcoin mining applications, ASIC chips are tasked to run simple math but do so iteratively, at a very fast rate. By using dedicated hardware such as an ASIC, a miner can get the best power/performance tradeoff.
- For machine learning applications, primarily developed by Google, called Tensor Processing Unit (or TPU).
CPUs: AMD, Intel and TSMC
Ok, back to our first chip type: the CPU. Although Apple has become an increasingly important player in this space, we will narrowly focus our discussion on AMD, Intel and TSMC.
“Real men have fabs†– Jerry Sanders (founder of AMD). The phrase has not aged well, so hasn’t the strategy of owning a fab (factory for chip making).
In the early 2000s, most large chipmakers had their own factory. This means they not only design their own chips, but also make them. They are what the industry calls an IDM (integrated device manufacturer). Because of a combination of rapidly increasing cost of building new fabs (nowadays, it costs more than US$15 billion of capital expenditures for a new fab) and decreasing market share, many companies gave up the fab business altogether:
- AMD decided to focus on design and spun off its manufacturing division into Global Foundries in 2008.
- IBM followed suit by selling its chip making business to Global Foundries in 2014.
Now, there are only a handful of these IDMs left, and Intel is one of the largest. Other chip design companies rely on Taiwan Semiconductor Manufacturing Company (TSMC) for manufacturing.
The loss of manufacturing capabilities of other firms has been a boon for TSMC, which became the de facto manufacturers for a lot of chip design companies (Apple, Nvidia, AMD, and others).
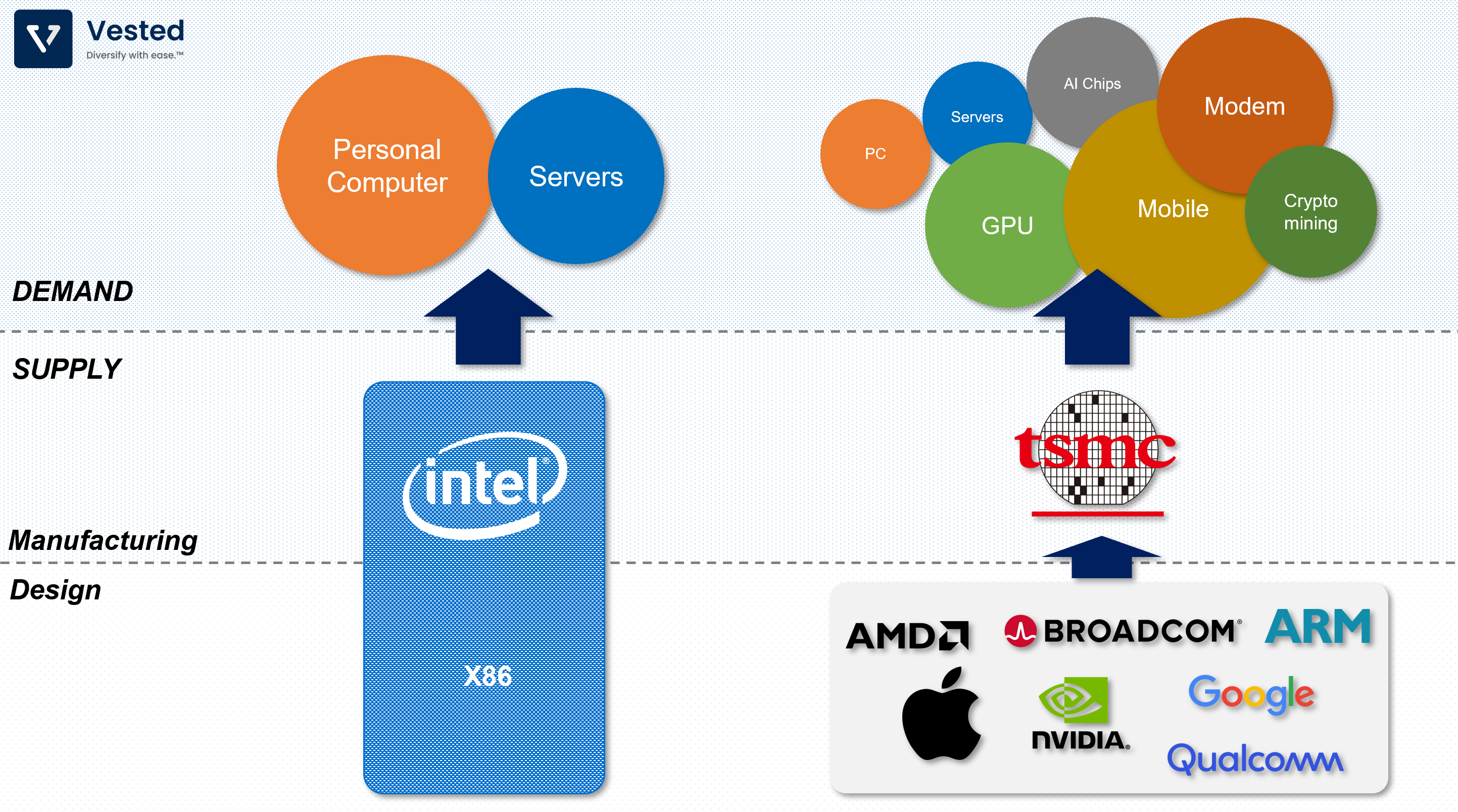
Let’s focus on the manufacturing aspect of the business.
Semiconductor manufacturers: Intel vs. TSMC
As we mentioned above, operating in the semiconductor manufacturing segment is highly expensive. You have to continue to spend heavily on R&D and capital expenditures. As a result, selling the highest chip volume is critical. The more chips you produce and sell, the more you can spread out your fixed investments. And the more volume you have, the more you can invest to continue to push new developments, leaving your competitors behind.
This is what TSMC has accomplished. In recent years, TSMC overtook Intel in total production volume and the capabilities of manufacturing the most advanced chips (which have better margins). This is because:
- TSMC makes chips for everyone, which means that they have more exposure to different compute platforms. So when the smartphone took over as the primary compute platform (replacing the PC), at the beginning of the last decade, its production volume surged. In contrast, Intel missed out on mobile, and after spending billions to enter the market, the company gave up.
- The rise of Nvidia and AI was also beneficial for TSMC, as TSMC is Nvidia’s manufacturing partner. Meanwhile, Intel is also lagging in AI.
- Intel has struggled with production issues to produce the latest (10 nm and 7 nm technology nodes). This led to multiple delays over the 2010s. The problem was Intel made the wrong technology bet. It decided to make these new technology nodes using the more traditional immersion lithography (through its long time supplier, Nikon). Meanwhile, TSMC worked with a Dutch company, ASML, the one company that has perfected extreme ultraviolet lithography (EUV). EUV has enabled a much faster production development timeline than other approaches. As a result, TSMC beat Intel to both the 10 nm and 7 nm nodes (note: ASML holds a monopoly of this EUV platform and sells one of its machines for more than US$150 million, with a 50% gross margin).
As a result of Intel’s stumbles, and TSMC’s continued execution, the Taiwanese company holds the semiconductor manufacturing crown. In the beginning of the last decade, TSMC was about 2 to 3 years behind in manufacturing capabilities, now it is 2 to 3 years ahead. And the company is starting to outspend Intel in capital expenditures (see Figure 3).
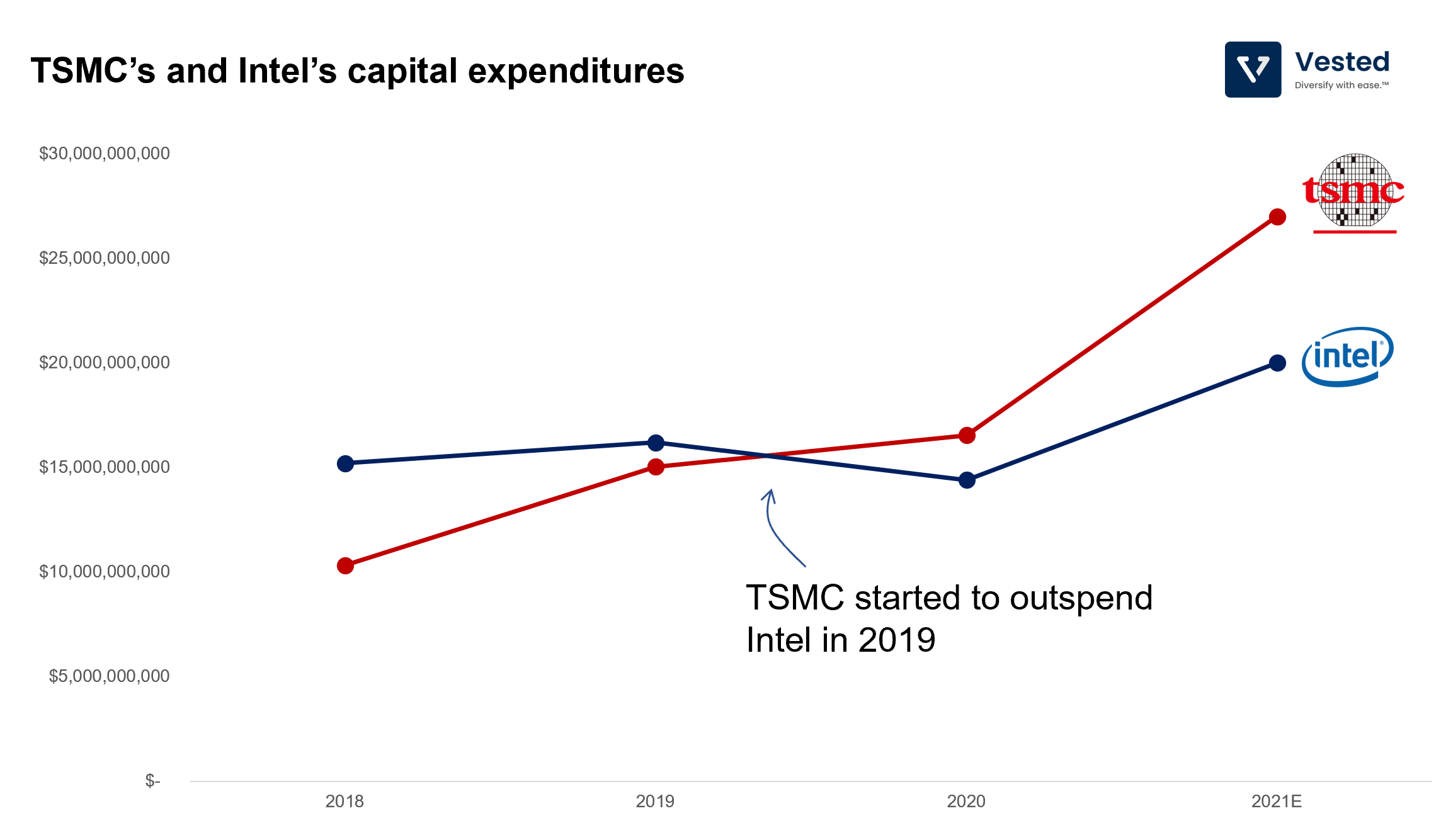
These struggles are why Intel has gone through two CEOs in the span of three years. The newest CEO, Pat Gelsinger (a person with technical roots, unlike the previous two), promised a revitalized Intel and a second attempt at becoming a manufacturing partner for other design companies (something that Intel had tried in 2013/2014 but failed) to compete with TSMC head on.
Now, let’s shift gears to the design aspect of the CPU.
CPU designers: AMD vs. Intel
Both Intel and AMD are the two companies that meaningfully compete on the PC and server market. The PC market is mature (no longer fast-growing), while the server market is the one that is fast growing (thanks to the growth of cloud computing). Therefore, the market growth for servers is the growth story for both companies.
Recall that the final chip performance is a function of the design and the manufacturing process. Intel’s manufacturing woes have caused it to delay its 10 and 7 nm nodes. Meanwhile, AMD, who is taking advantage of TSMC’s production prowess, continues to release products that are not only cheaper, but better. See Figure 4 for a performance comparison between AMD’s top of the line server product vs Intel’s.
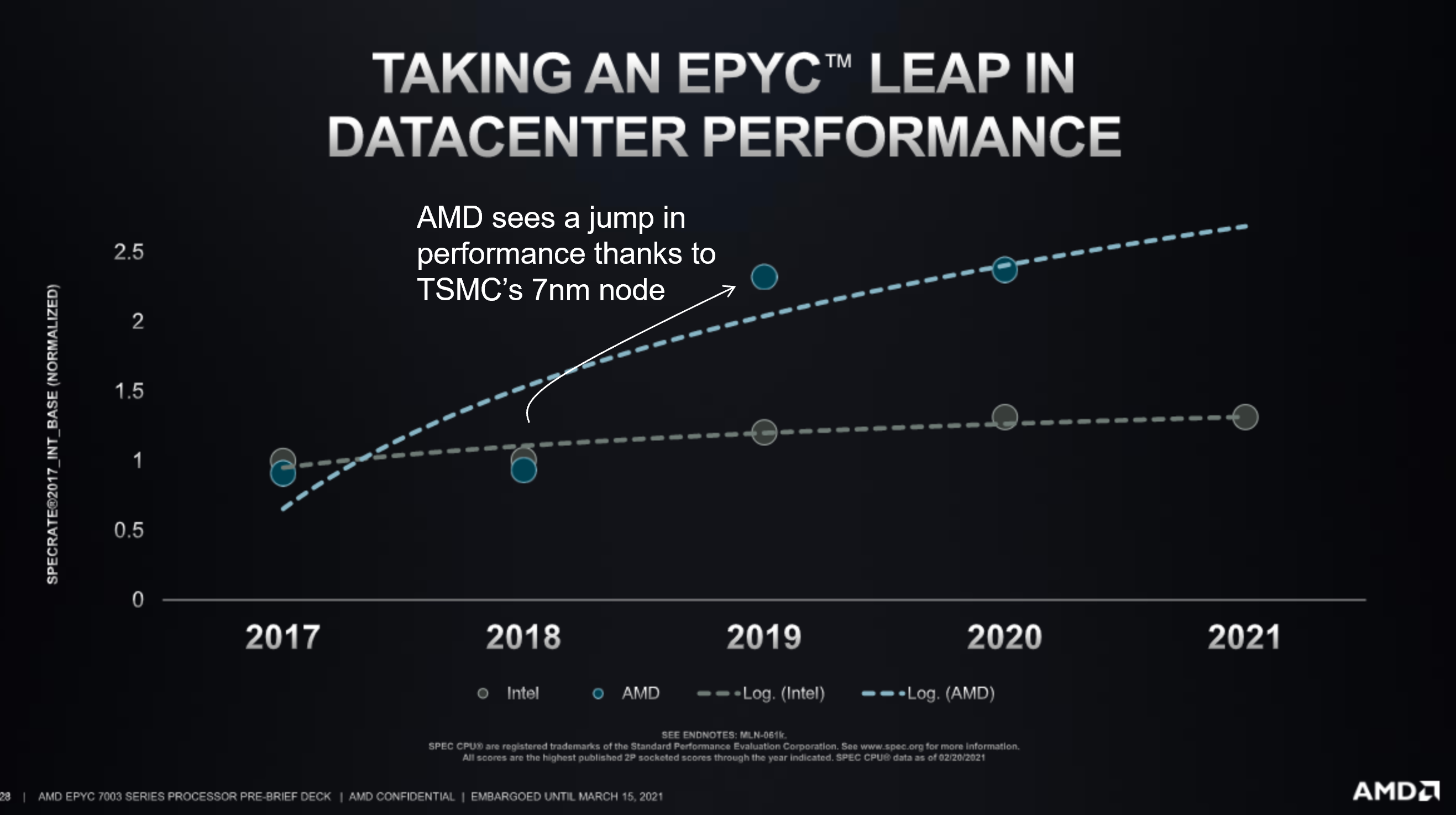
AMD’s performance (blue dots) are actually on par with Intel’s (grey dots) in 2017 and 2018. But in 2019, AMD’s product made a leap. This was the first product that took advantage of TSMC’s 7 nm node. Meanwhile, Intel’s performance improvement has not been as strong. Intel’s design is being held back by its manufacturing woes. On top of that, AMD is undercutting Intel on price. On average, AMD’s chips are selling anywhere between 30 – 50% cheaper than Intel’s equivalent.
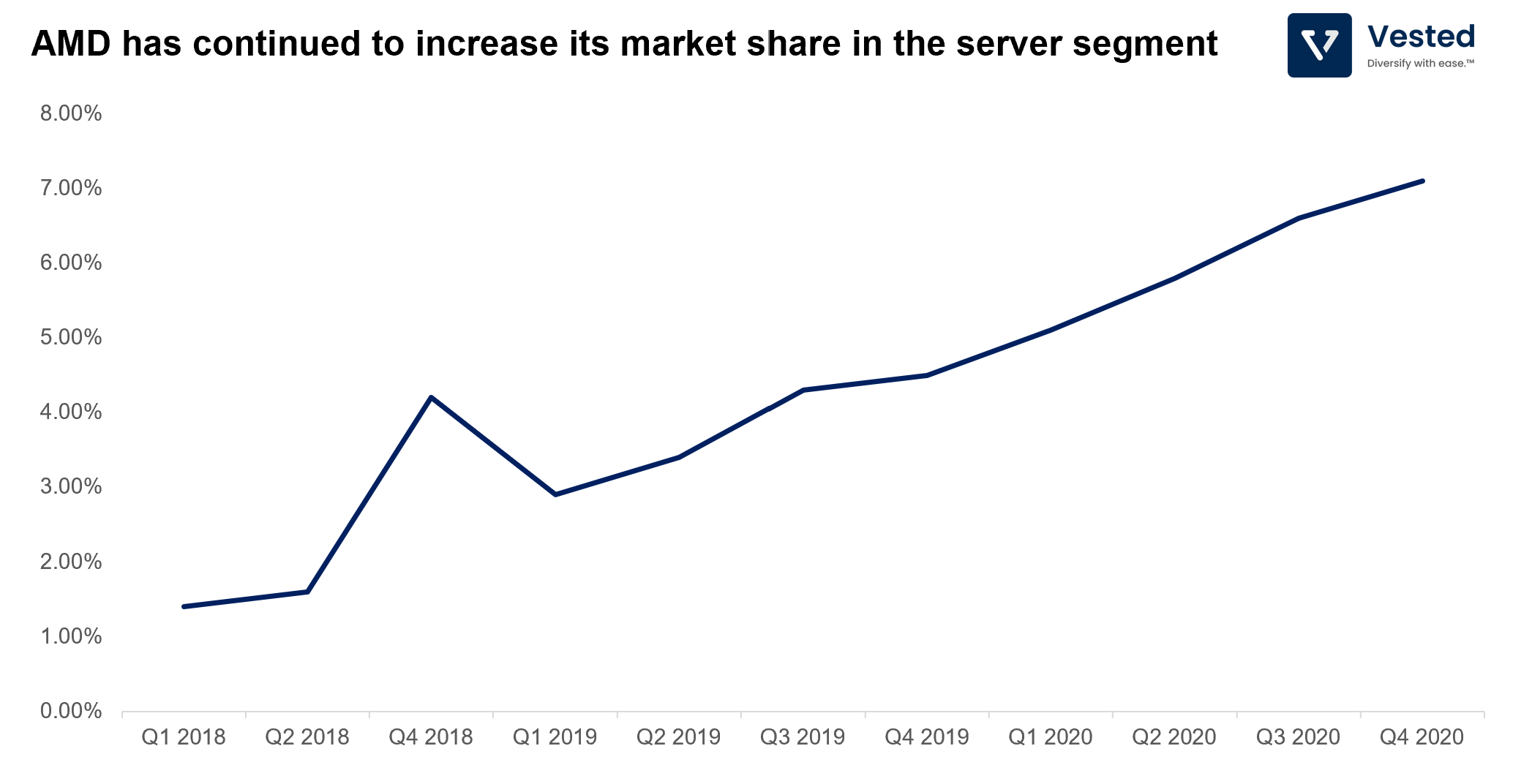
For cloud providers such as Amazon, Google, Baidu, and Microsoft, lower price and better performance means they can do more with less (less power consumption, less heat, less number of CPUs). As a result, AMD has been growing its market share in the server segment, from ~1% in 2018 to more than 7% in Q4 2020 (Figure 5). This is AMD’s growth story. Note: Intel is still the juggernaut in this vertical, however, with ~93% market share in this segment.
GPUs: Nvidia
Let’s pick up where we left off with Nvidia. The company makes money through five segments: Gaming, Professional Visualization, Data Center, Automotive (for self driving car applications), OEM & Other.
The two key segments for Nvidia’s growth are Gaming (dark blue in Figure 6), which contributes 47% or total revenue in the last FY), and Data Center (blue in Figure 6), which contributes 40% of total revenue in the last FY).
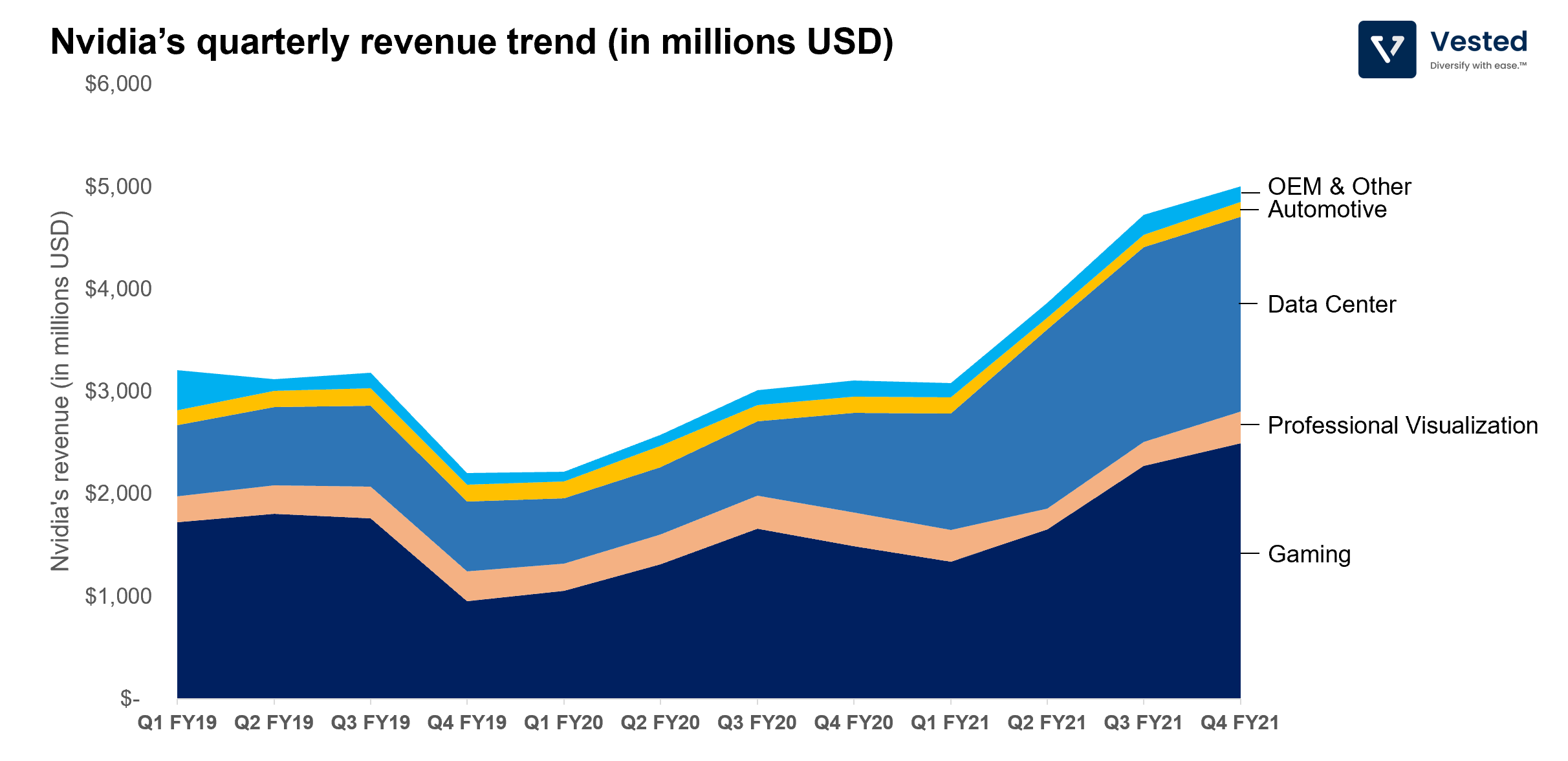
On Gaming: Gaming is big business. In 2020 alone, the total addressable market in the gaming segment was US$180 billion, more than sport and movies combined. But for Nvidia, revenue on this segment is not driven from gaming alone. Nvidia’s GPU has also become the mining tool of choice to mine cryptocurrencies. It’s speculated that Nvidia saw about 2 – 5% revenue lift from the crypto mining boom.
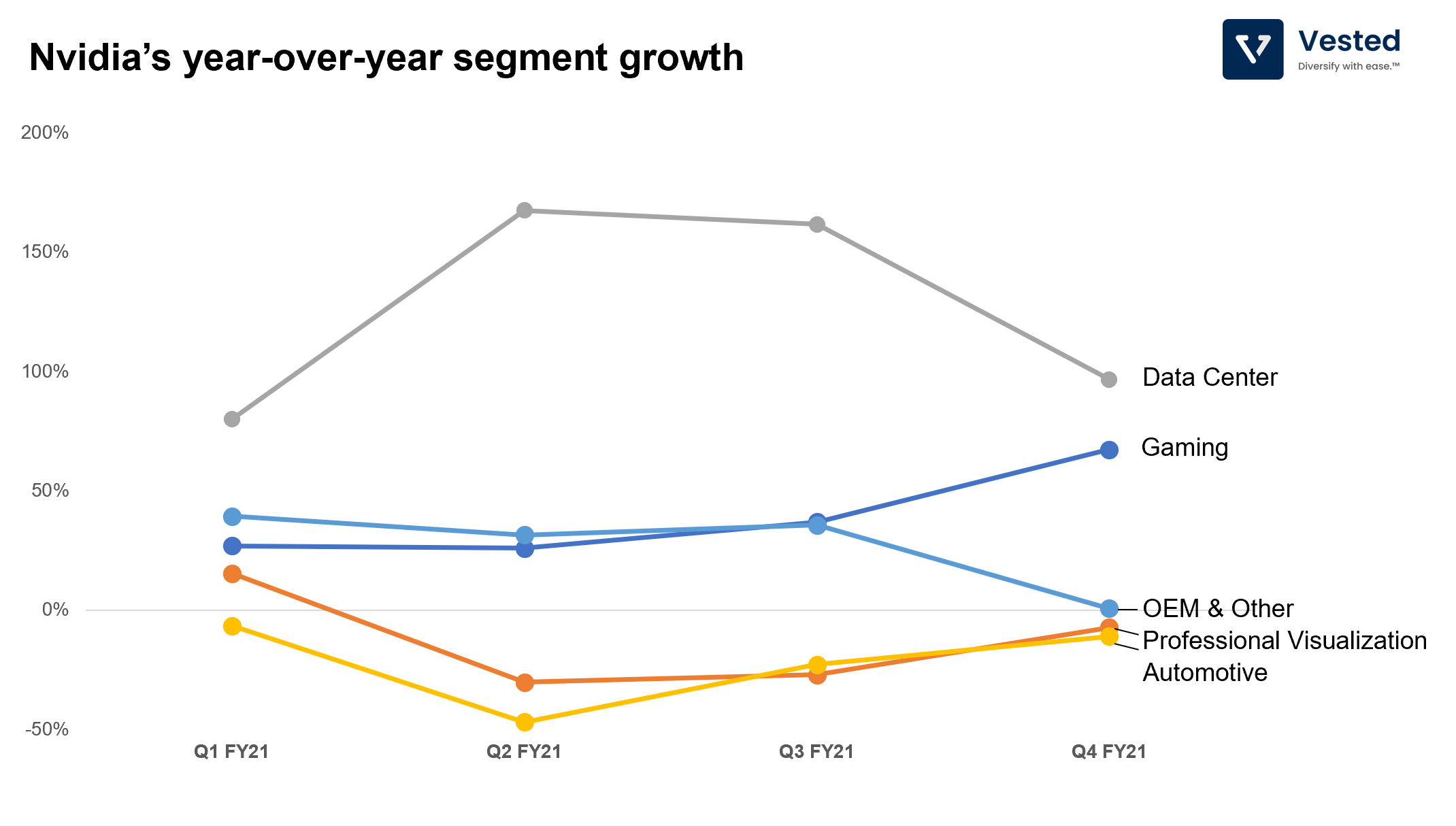
On Data Center: After Andrew Ng’s seminal paper in 2009, researchers started to use GPUs, specifically Nvidia’s GPU, for AI research. Because of this, many open source machine learning tools are compatible with Nvidia’s GPUs. In 2015, the company released its first machine learning hardware, and as more and more machine learning workload moves to the cloud, so has Nvidia’s efforts into the data center segment. This segment has been the primary engine of growth for the company. The year-over-year revenue growth for this segment has been more than 100% in the past 3 quarters – see Figure 7.
Nvidia’s primary product into the data center has been AI accelerators. These products help you develop, train and execute machine learning models much faster than traditional CPUs that AMD or Intel make. You still need to run CPUs along with the GPUs for machine learning applications, however. So, by large, Nvidia is not directly competing with Intel or AMD in the Data Center vertical.
But that is about to change:
- Over time, in pursuit of ever-increasing accuracy, the size of both training data sets and machine learning models are increasing. The latest, most advanced language model (GPT-3) has 175 billion parameters and was trained with 45 terabytes worth of data from the internet.
- In AI/ML, model training is an iterative process, where training data and parameters of the models are shuttled between memory and the processing unit millions of times until the desired accuracy is achieved.
- Not only that, separation of memory from the CPU means that performance is limited by the transfer speed between the two. This is called the von Neumann bottleneck.
- Moreover, moving data from memory to the compute unit consumes a lot of energy (~500x more than the energy it would take to process said data).
- These trends worsen when the chip scales.
So, if phase 1 of Nvidia’s Data Center strategy is to create AI accelerator products. Phase 2 is to enter the CPU space themselves to compete directly with Intel and AMD and mitigate the bottlenecks above. Nvidia plans to do so through the ARM acquisition and Project Grace (Figure 8). See more below.
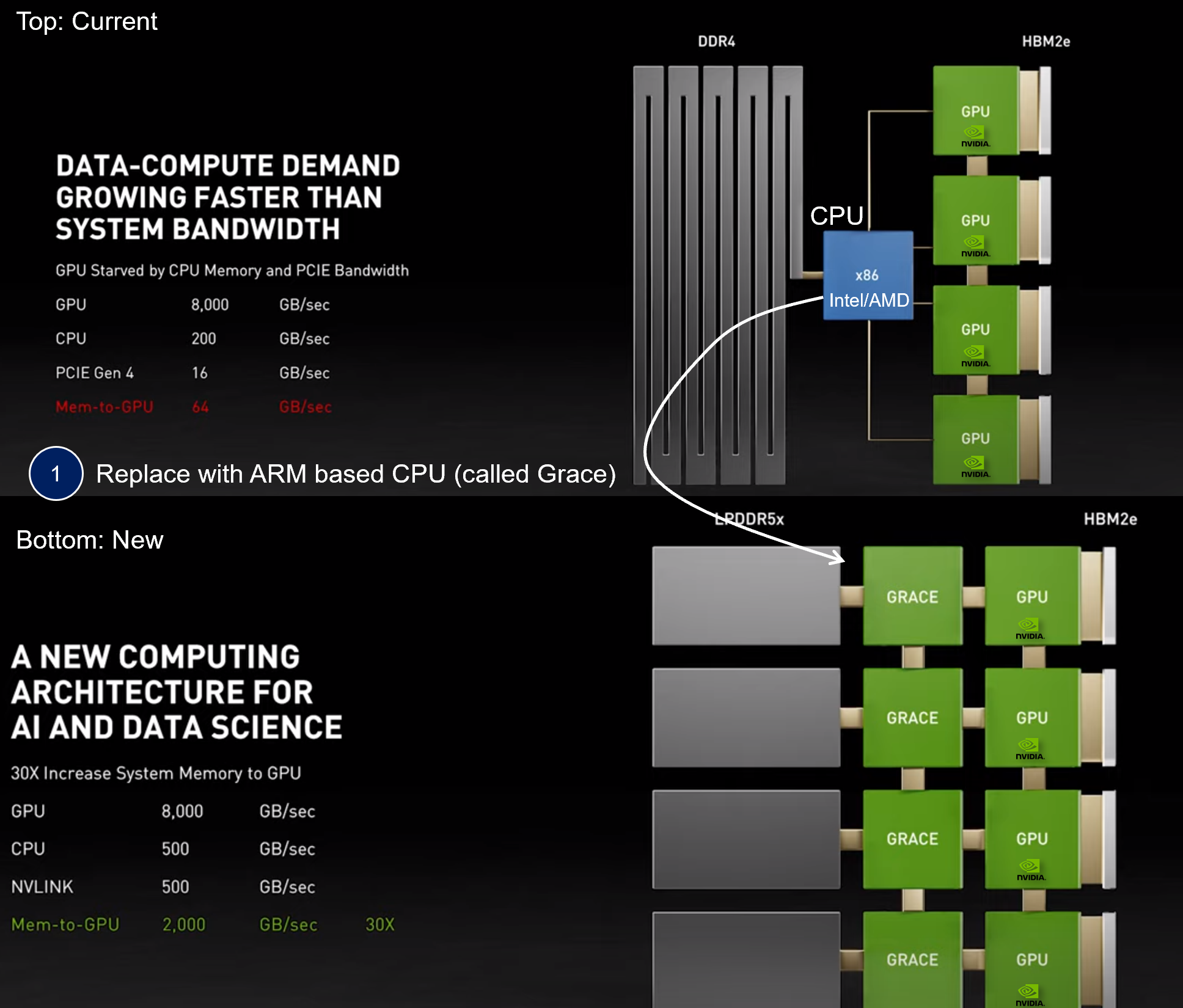
- The top image shows the current typical CPU/GPU combo for AI applications.
- The CPU is X86 architecture, typically made by either Intel or AMD. The GPUs are Nvidia’s.
- As discussed above, transfer of memory is increasingly becoming the bottleneck due to the size of the data and the model (represented by the thin lines connecting the different modules in Figure 8).
- So, Nvidia proposes to use its proprietary data connector (called NVLink), which is not compatible with Intel’s / AMD’s CPU but is much faster. Therefore, Nvidia is making a CPU alternative, using out of the box ARM architecture that can be used in conjunction with NVlink, increasing the transfer speed (from memory to the GPU) by 30x. This is the bottom image.
- In order to do this, Nvidia has to invest in ARM development, which makes ARM more valuable. To be able to better capture the upside, the company then decided to buy ARM (although this acquisition is now being scrutinized by regulators over antitrust concerns).
Even if the acquisition does not go through, the company is committed to ARM CPU development and is working together with Amazon to further develop these products. This will open up another workload segment for Nvidia within the fast-growing Data Center segment.
